GSpread DBMS
This Python module is a Class implementation for using Google Spreadsheet as a pseudo- DataBase Management System (DBMS). It provides most of the basic functionalities of DBMS like inserting rows, retrieve rows and columns, updating cells, querying the DB based on conditions etc. Due to the inherent nature and purpose of Google Spreadsheet, it is not possible to operate as a high performance DBMS. However, this is suitable for low number of input/output (I/O) operations requirement (say 100 ops per 100 seconds) and preferably no concurrent write operations. For a Database, building an efficient and feature-rich fronted is a very tedious task, having the option to use the powerful Google Spreadsheet interface is a huge advantage while sacrificing some I/O performance by backend programs.
There are specific features built in this package to overcome some of the I/O limitations:
- Implementation of DBMS read caching system - Read rows and columns are cached for small time period, so that repeated read operation can be served quickly and without sending multiple read request to our DB. The cache duration is modifiable
cache_durationand also the cache is flush-able by user if needed during runtime_flush_cache(..). - Batch write operation - Function is provided to accumulate multiple write operations in a buffer
update_cell_Buffered(..), and then execute all in a single batchupdate_cell_BufferCommit(). This way we are improving performance and only utilizing one actual write operation.
Documentation
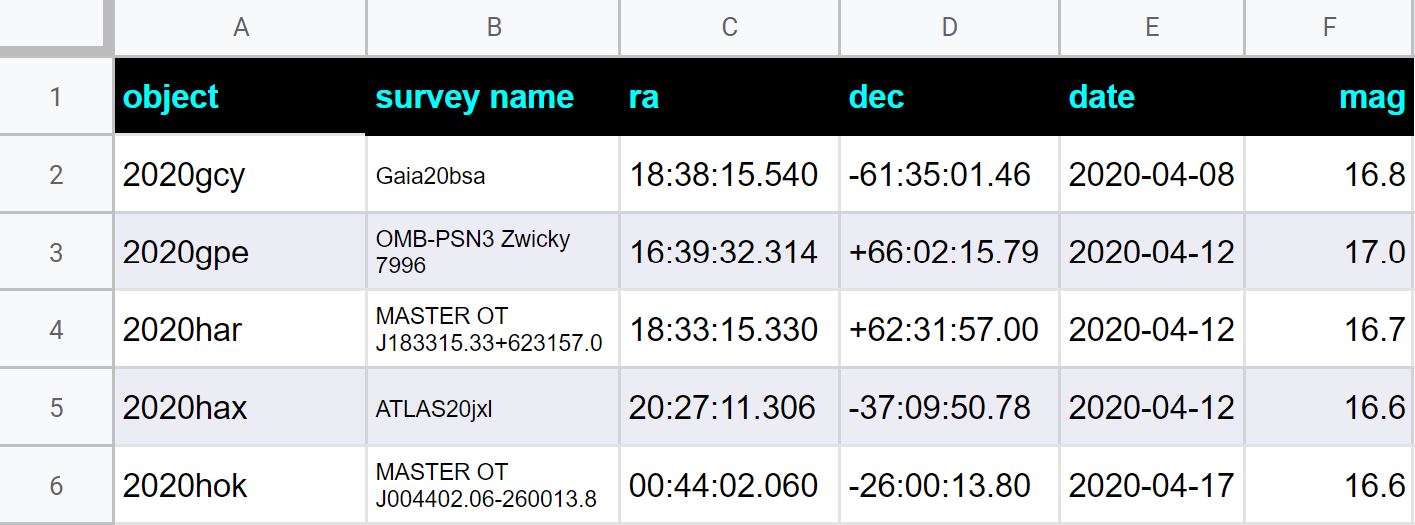
Let's take an example of the above Google Spreadsheet. Below we show examples of various operations and queries we can perform on this table.
Starting a Database instance
from gspread_dbms import GSpreadDBMS
GDB=GSpreadDBMS(
ssid='ID', # Spreadsheet ID
key='KEY_FILE', # File name or parsed JSON of the Key for the google service account.
# Below are the optional parameters. Default values are shown here
worksheet=1, # Workseet name/number.
headrow=1, # Row number of column names header
startrow=2, # Data start row
EnableCache=True, # Caching to be enabled or dsabled
verbose=False # Whether to turn on verbosity
)
ssid - is the ID of the Google Spreadsheet you can find in the URL.
key - This is key you need to obtain from service account in google developer console. Make sure this service account is given edit permission in the google spreadsheet.
Insert rows
Inserting a row where values are given for each column in a dict. You may opt out a column name to leave it blank. Insertion are always at the top of the table by default.
GDB.insert_row({'object':'2020gcy', # 2020gcy inserted in column 'object'
'survey name': 'Gaia20bsa', # Similarly for 'survey name' column
'ra': '18:38:15.540', # Similarly for 'ra' column
'dec':'-61:35:01.46'}) # Similarly for 'dec' columnSelecting row
Returns the row number given by a value equal to '2020har' in column 'object'.
Note: row number is always with reference to the data start row specified above.
>>> GDB.find_row('2020har', 'object')
3Read column
Reading an entire column specified by column name
GDB.read_col('object')Read row
Reading an entire row specified by row number
GDB.read_col(3)or you can combine with find_row(...) function to read row by a value
GDB.read_col( GDB.find_row('2020har', 'object') )Querying based on conditions
It is possibly to do wide range of simple to complex conditional queries
# Function definition
GDB.query(select_keys, # List of Columns/Keys which should be returned
query_key_val=None, # Dict of list of keys and condition to apply
date_fmt=None) # Optional - if condtions are based on date in a column, you may want to specify a date format. Default is ISO format.Examples:
This will return all rows for selected columns without applying any conditions
GDB.query(['object', 'ra', 'dec'])This will return all rows based on arithmetic condition on 'Mag' column.
GDB.query(['object', 'ra', 'dec'], {'mag': '<=16.7'}) # mag <=16.7
# or
GDB.query(['object', 'ra', 'dec'], {'mag': '16.7'}) # mag == 16.7
# or
GDB.query(['object', 'ra', 'dec'], {'mag': '=16.7'}) # mag == 16.7
# or
GDB.query(['object', 'ra', 'dec'], {'mag': '>16.7'}) # mag > 16.7
# or
GDB.query(['object', 'ra', 'dec'], {'mag': '!=16.7'}) # mag not equal to 16.7This will return all rows based on date comparison. Supports all arithmetic inequalities.
GDB.query(['object', 'ra', 'dec'], {'date': '2020-04-12'})
# or
GDB.query(['object', 'ra', 'dec'], {'date': '<2020-04-12'})This will return all rows based on string comparison.
GDB.query(['object', 'ra', 'dec'], {'object': '2020har'}) # equals to a value
# or
GDB.query(['object', 'ra', 'dec'], {'object': '!=2020har'}) # not equals to a valueother operators can be used too, like =, <, >, < =, >= etc., which will lead to string comparisons.
Following will return all rows for values found in given list of strings.
GDB.query(['object', 'ra', 'dec'], {'object': ['2020har', '2020hax']})This will return all rows for values passed onto a function and which returns True
def MyFunc(value):
# A demo function to check if Hour part of the RA is 16<= Hour <=18
tmp=value.split(':')
Hrs=float(tmp[0])
if Hrs>=16 and Hrs<=18:
return True
else:
return False
GDB.query(['object', 'ra', 'dec'], {'ra': MyFunc})Updating single cell
GDB.update_cell (rownum, # Row number w.r.t. start-row
colname, # Column name
value) # Value to update in the cellExample:
GDB.update_cell (3, 'ra', '18:33:15.330')Updating entire row
GDB.update_row (rownum, # Row number w.r.t. start-row
values) # A dict of Values to update in the cellExample:
GDB.update_row (1,
{'survey name': 'Gaia20bsa', 'ra': '18:38:15.540'})Updating cells in batch
First we put the cell update operations in buffer, without actually making changes in the database.
# Syntax is same as update_cell( ... ) function.
GDB.update_cell_Buffered (3, 'ra', '18:33:15.330')
GDB.update_cell_Buffered (2, 'object', '2020gpe')
GDB.update_cell_Buffered (4, 'dec', '-37:09:50.78')
GDB.update_cell_Buffered (3, 'object', '2020har')Then we commit all operation in a single go.
GDB.update_cell_BufferCommit()Cache control
Changing read cache duration. Default is 10 seconds.
GDB.cache_duration = 60 # Changing to 60 seocondsFlush cache for a row and/or column or everything. Syntax is:
GDB._flush_cache(row=ROW-NUMBER,col=COL-NAME)Examples:
# Flush cache for a row number
GDB._flush_cache(row=2)
# Flush cache for a column name
GDB._flush_cache(col='ra')
# Flush cache for a row and a column both
GDB._flush_cache(row=2,col='dec')
# Flush all cache
GDB._flush_cache()Delete rows
To be added.
Insert row at a given position
To be added.